前言
Java后端技术点
StringUtils常用API
学习时笔记(Linux)
学习时笔记(Git)
学习时笔记(Docker)
学习时笔记(Vue2+3)
面试宝典
学习时笔记(JavaScript)
学习时笔记(JavaWeb)
学习时笔记(Java)
学习时笔记(Python)
1.Python入门
2.Python基础语法
3.Python判断语句
4.Python循环语句
5.Python函数
6.Python数据容器
7.Python函数进阶+文件操作
8.Python异常+模块与包
9.案例:折线图+地图+柱状图
10.面向对象
11.PySpark
12.高阶技巧
13.爬虫-urllib
14.爬虫-解析+selenium+requests
15.爬虫-scrapy
1.函数多返回值
- 定义使用
def manyReturn():
return 1, "hello", True
x,y,z = manyReturn()
print(f"{x}\t{y}\t{z}")
- 注意点
- 按照返回值的顺序,写对应顺序的多个变量接收即可
- 变量之间用逗号隔开
- 支持不同类型的数据return
2.函数多种传参方式
位置参数
- 调用函数时,根据函数定义的参数位置来传递参数(一直使用的)
def userInfo(name,age,gender): print(f"姓名是:{name},年龄是:{age},性别是:{gender}") # 位置参数 -默认使用方式 userInfo("马浩楠",22,"男")传递的参数和定义的参数的顺序及个数必须一致
关键字参数
- 函数调用时,通过 ”键 = 值“的形式传递参数
- 可以让函数更加清晰、容易使用,同时也清楚了参数的顺序需求
# 关键字参数 userInfo(name="马浩楠",age=22,gender="男") userInfo(age=22,name="马浩楠",gender="男") userInfo("马浩楠",age=22,gender="男")函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序
缺省参数
- 缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(注意所有位置参数必须出现在默认参数前,包括函数定义和调用)
- 当调用函数时没有传递参数,就会使用默认值
# 缺省参数 def userInfo(name,age,gender = "男"): print(f"姓名是:{name},年龄是:{age},性别是:{gender}") userInfo("马浩楠",22)不定长参数
- 可变参数,用于不确定调用时会传递多少个参数(不传参也可以)的场景
- 当调用函数时不确定参数个数时,可以使用不定长参数
- 位置传递
# 不定长 -位置不定长 *号 def userInfo(*args): print(args) userInfo(1,"Hello",True)传递的所有参数都会被args变量收集,根据传进参数的位置合并为一个元组类型
- 关键字传递
# 不定长 -关键字不定长 **号 def userInfo(**kwargs): print(kwargs) userInfo(name="马浩楠",age=22,gender="男")参数是”键 = 值“形式的情况下,所有的键值对都会被kwargs接收,组成字典类型容器
3.匿名函数
3.1、函数作为参数传递
- 示例
# 定义函数,接收另一个函数作为形参
def test(calculate):
result = calculate(1,3)
print(f"参数的函数类型是:{type(calculate)}")
print(f"计算结果:{result}")
# 定义函数,作为参数传入另一个函数
def calculate(x,y):
return x+y
# 调用,并传入函数
test(calculate)
函数calculate,作为参数,传入test函数中使用
- test 需要一个函数作为参数传入,这个函数需要接收两个数字进行计算,计算逻辑由被传入的函数决定
- calculate函数接收2个数字对齐进行计算,作为参数传递给test函数使用
- 计算逻辑的传递,而非数据的传递
3.2、lambda匿名函数
- 函数定义
- def 关键字,可以定义带有名称的函数
- lambda关键字,可以定义匿名函数(无名称)
有名称的函数,可以基于名称重复使用,无名称的匿名函数,只能临时使用一次
语法
lambda 传入参数: 函数体(一行代码)- lambda 关键字,表示定义匿名函数
示例
# 定义一个函数,接收其它函数输入
def test(calculate):
result = calculate(4,5)
print(f"结果是:{result}")
# 通过lambda匿名函数的形式,将匿名函数作为参数传入
test(lambda x, y: x * y)
4.文件的读取
open() 打开函数
open(name,mode,encoding)- name:是要打开的目标文件名的字符串(可以是绝对路径也可以相对路径)
- mode:打开文件的模式:读、写、追加
- encoding:编码格式(大部分是UTF-8)
示例
# 打开文件
f = open("./data.txt","r",encoding="utf-8")
此时的 f 是 open函数的文件对象
- mode常用的三种基础访问模式

4.1、读
read()方法:文件对象.read(num)
num表示要从文件中读取的数据长度(字节),如果没有传入um,则表示读取文件中所有数据
# 打开文件 f = open("./data.txt","r",encoding="utf-8") # 读取文件 - read() print(f.read(2)) print(f.read())readlines()方法
按照行的方式吧整个文件的内容进行一次性读取,并返回列表,每一行的数据为一个元素
# 多次使用read方法,会影响内容,已经读取过的内容不会继续读取 # 读取文件 - readLines() lines = f.readlines() print(lines)readline()方法:一次读取一行内容
# 读取文件 - readLine() line1 = f.readline() line2 = f.readline() line3 = f.readline() print(f"读取第一行数据:{line1}") print(f"读取第二行数据:{line2}") print(f"读取第三行数据:{line3}")for 循环读取文件行
# for循环读取文件行 for i in f: print(f"每一行的数据是:{i}")close() 与Java一致
with open 语法
通过在with open的语句块中对文件继续操作,在操作完成后自动close文件,避免遗忘掉close方法
with open("./data.txt","r",encoding="utf-8") as f: for i in f: print(f"每一行:{f}")操作总览
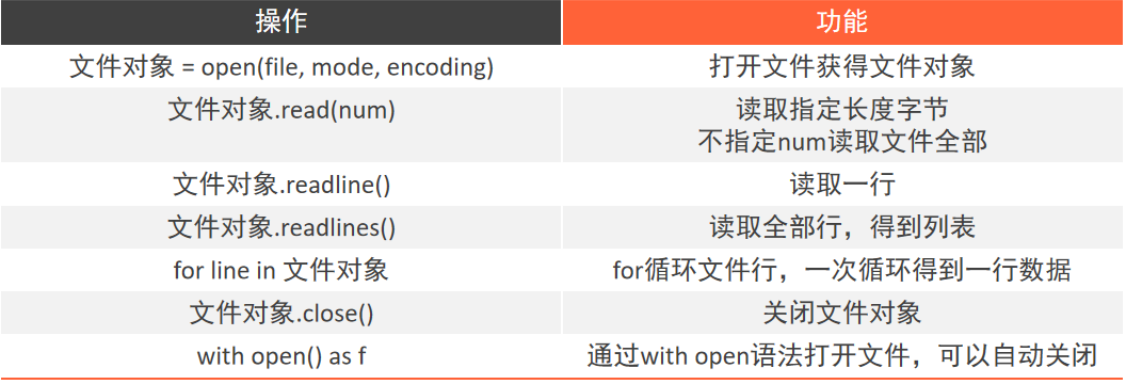
- 练习

with open("./wordsCount","r",encoding="utf-8") as f:
count = 0
for i in f:
count += i.count("itheima")
print(f"itheima出现的次数是:{count}")
# 方式二:
print(f.read().count("itheima"))
5.文件的写入
- 示例
# 打开文件(不存在的)
f = open("./write.txt","w",encoding="UTF-8")
# write 写入
f.write("Hello World")
# flush 刷新
#f.flush() # 将内存中积攒的内容,写入到硬盘的文件当中
# close 关闭
f.close() # 内置 flush()
# 打开一个存在的文件
f = open("./data.txt","w",encoding="utf-8")
# write写入、flush刷新
f.write("婚姻:否")
# close 关闭
f.close()
- 注意点
- 直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
- 当调用flush的时候,才会真正写入文件
- 这样做是为了避免频繁的操作硬盘,导致效率下降
6.文件的追加
将模式改为 a 即可
7.文件操作综合案例

- 需求
- 读取文件
- 将文件写出到bill.txt文件作为备份
- 同时,将文件内标记为测试数据丢弃
w = open("./bill.txt","w",encoding="UTF-8")
with open("./comsumerData.txt","r",encoding="UTF-8") as f:
for i in f:
if i.count("测试") != 1:
w.write(i)
w.close()
f.close()
7-