前言
Java后端技术点
StringUtils常用API
学习时笔记(Linux)
学习时笔记(Git)
学习时笔记(Docker)
学习时笔记(Vue2+3)
面试宝典
学习时笔记(JavaScript)
学习时笔记(JavaWeb)
学习时笔记(Java)
学习时笔记(Python)
1.Python入门
2.Python基础语法
3.Python判断语句
4.Python循环语句
5.Python函数
6.Python数据容器
7.Python函数进阶+文件操作
8.Python异常+模块与包
9.案例:折线图+地图+柱状图
10.面向对象
11.PySpark
12.高阶技巧
13.爬虫-urllib
14.爬虫-解析+selenium+requests
15.爬虫-scrapy
1.Spark前沿
- 概述
- Apache Spark 是用于大规模数据处理的统一分析引擎
- Spark 也可以说是一款分布式的计算框架,用于调用成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据
2.Spark基础准备
PySpark库安装
- cmd—— pip install pyspark
构建PySpark执行环境入口对象
- 想要使用PySpark库完成数据处理,首先需要构建一个执行环境入口对象
- PySpark的执行环境入口对象是:SparkContext对象
# 导包 from pyspark import SparkConf,SparkContext # 创建SparkConf类对象 conf = SparkConf.setMaster("local[*]").setAppName("testSpark") # 基于SparkConf类对象创建SparkContext对象 sc = SparkContext(conf=conf) # 打印PySpark的运行版本 print(sc.version) # 停止SparkContext对象的运行(停止PySpark工作) sc.stop()PySpark的编程模型

3.数据输入
- RDD对象
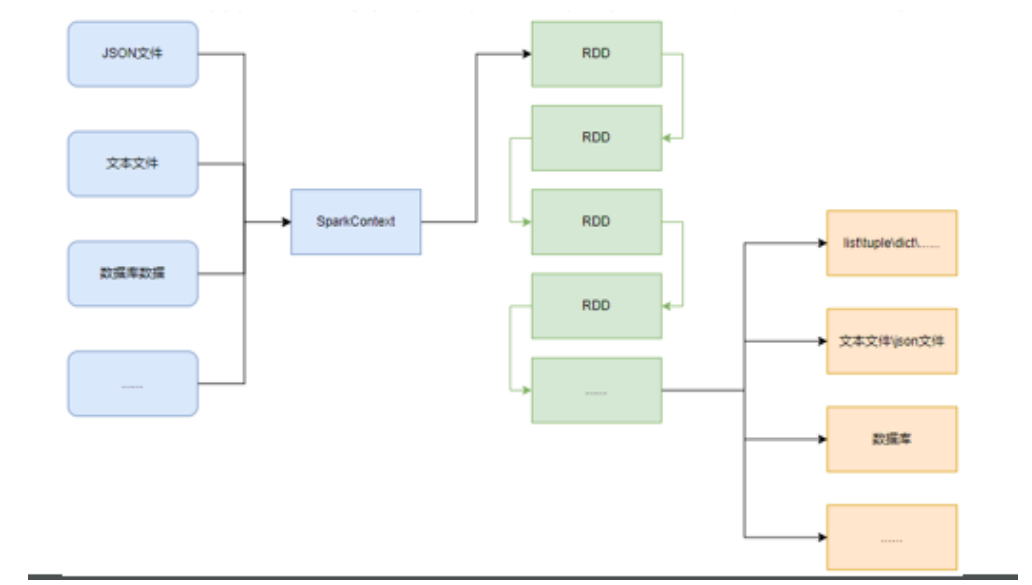
如图见,PySpark支持多种数据的输入,在输入完成后,都会得到一个RDD类的对象
RDD全称:弹性分布式数据集
RDD的数据计算方法,返回值依然是RDD对象,支持链式
Python数据容器转RDD对象
from pyspark import SparkConf,SparkContext conf = SparkConf().setMaster("local[*]").setAppName("testSpark") sc = SparkContext(conf=conf) # 通过parallelize方法将Python对象加载到SPark内,成为RDD对象 rdd1 = sc.parallelize([1,2,3,4,5]) rdd2 = sc.parallelize((1,2,3,4,5)) rdd3 = sc.parallelize("mahaonan") rdd4 = sc.parallelize({1,2,3,4,5}) rdd5 = sc.parallelize({"key1":"value1","key2":"value2"}) # 如果要查看RDD里面有什么内容,需要用collect()方法 print(rdd1.collect()) print(rdd2.collect()) print(rdd3.collect()) print(rdd4.collect()) print(rdd5.collect()) sc.stop()- 注意
- 字符串会被拆分为1个个的字符,存入RDD对象
- 字典仅有key会被存入RDD对象
- 读取文件转RDD对象
from pyspark import SparkConf,SparkContext conf = SparkConf().setMaster("local[*]").setAppName("testSpark") sc = SparkContext(conf=conf) # 通过textFile方法,读取文件数据加载到Spark内,成为RDD对象 rdd = sc.textFile("./introduce.txt") print(rdd.collect()) sc.stop()- 注意
4.数据计算
4.1、map方法
map算子
- 将RDD数据一条条处理(处理的逻辑基于map算子中接受的处理函数),返回新的RDD
示例代码
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "E:\Python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("testSpark")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([1,2,3,4,5])
# 通过map方法将全部数据*10
# def func(data):
# return data*10
rdd1 = rdd.map(lambda data:data*10)
print(rdd1.collect())
# 通过map方法将全部数据*10再+5
# 链式调用
rdd1 = rdd.map(lambda data:data*10).map(lambda data:data+5)
print(rdd1.collect())
- 对于传入参数时,可以选择
- 定义方法,传入其方法名
- 使用lambda匿名方法的方式【推荐】
4.2、flatMap方法
flatMap算子
- 对RDD执行map操作,然后进行解除嵌套操作
解除嵌套
list = [[1, 2, 3],[4, 5, 6],[7, 8, 9]] # 如何解除嵌套 list = [1,2,3,4,5,6,7,8,9]示例代码
from pyspark import SparkConf,SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "E:\Python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("testSpark")
sc = SparkContext(conf=conf)
rdd = sc.parallelize(["mahaonan haonan 111","mahaonan mahaonan haonan","python mahaonan"])
# 需求:将RDD数据里面的一个个单词提取出来 (解除嵌套操作)
print(rdd.flatMap(lambda data:data.split(" ")).collect())
#['mahaonan', 'haonan', '111', 'mahaonan', 'mahaonan', 'haonan', 'python', 'mahaonan']
4.3、reduceByKey方法
- reduceByKey算子
- 针对KV型的RDD,自动按照key分组,然后根据提供的聚合逻辑,完成组内数据(value)的聚合操作
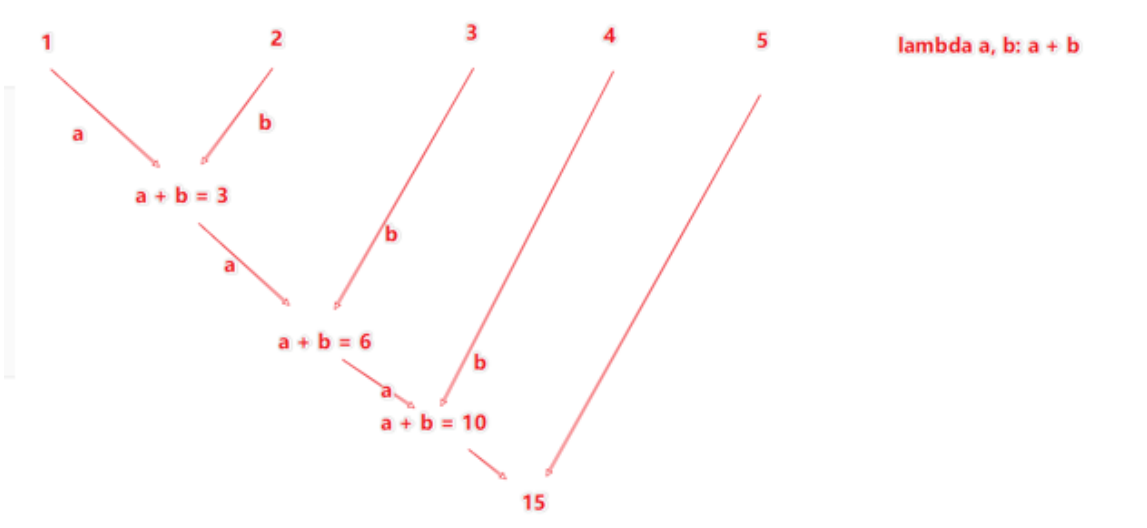
- 示例代码
from pyspark import SparkConf,SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "E:\Python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("testSpark")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([("男生", 80),("男生", 99), ("女生", 102), ("女生", 99)])
# 求男生和女生两个租的成绩之和 (reduceByKey 分组聚合)
print(rdd.reduceByKey(lambda x, y:x+y).collect())
- 注意
- reduceByKey中接受的函数,只负责聚合,不理会分组
4.4、练习案例1
- 使用学习到的
- 读取文件
- 统计文件内,单词出现的数量
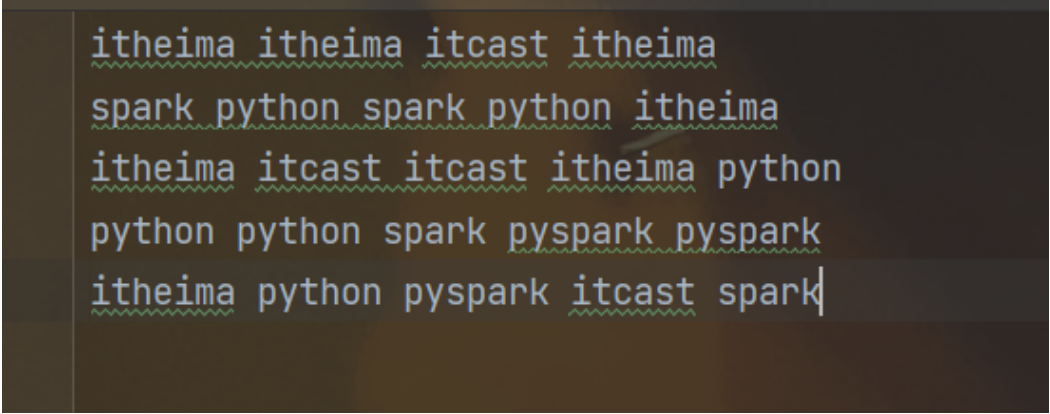
from pyspark import SparkConf,SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "E:\Python3.10.4\python.exe"
# 1. 构建执行环境入口对象
conf = SparkConf().setMaster("local[*]").setAppName("testSpark")
sc = SparkContext(conf=conf)
# 2.读取数据文件
rdd = sc.textFile("./hello.txt")
# 3.取出全部单词
rdd = rdd.flatMap(lambda data:data.split(" "))
# 4.将所有单词都转换成二元元租,单词为key,value设置为1
words_rdd = rdd.map(lambda data:(data,1))
# 5.分组并求和
rdd = words_rdd.reduceByKey(lambda a, b:a+b)
# 6.打印输出结果
print(rdd.collect())
4.5、filter方法
- 过滤想要的数据进行保留
- 匿名发放中的返回值为True保留,False丢弃
- 示例代码
from pyspark import SparkConf,SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "E:\Python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("testSpark")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,2,3,4,5,6,7])
# 对rdd对象中数据进行过滤(过滤偶数)
result = rdd.filter(lambda data:data%2 == 0)
print(result.collect())
4.6、distinct方法
- 对RDD数据进行去重,返回新的RDD,无参即可
- 示例代码
from pyspark import SparkConf,SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "E:\Python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("testSpark")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,1,3,3,4,5,5,8,6,6,7,7])
# 对rdd对象中数据进行去重(无需参数)
result = rdd.distinct()
print(result.collect())
4.7、sortBy方法
- 对RDD数据进行排序,基于指定的排序一句
- 示例代码
from pyspark import SparkConf,SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "E:\Python3.10.4\python.exe"
# 1. 构建执行环境入口对象
conf = SparkConf().setMaster("local[*]").setAppName("testSpark")
sc = SparkContext(conf=conf)
# 2.读取数据文件
rdd = sc.textFile("./hello.txt")
# 3.取出全部单词
rdd = rdd.flatMap(lambda data:data.split(" "))
# 4.将所有单词都转换成二元元租,单词为key,value设置为1
words_rdd = rdd.map(lambda data:(data,1))
# 5.分组并求和
rdd = words_rdd.reduceByKey(lambda a, b:a+b)
# 6.进行排序
result = rdd.sortBy(lambda data:data[1], ascending=False, numPartitions=1)
print(result.collect())
- ascending:True 升序,False 降序
- numPartition:用多少分区排序
4.8、练习案例2
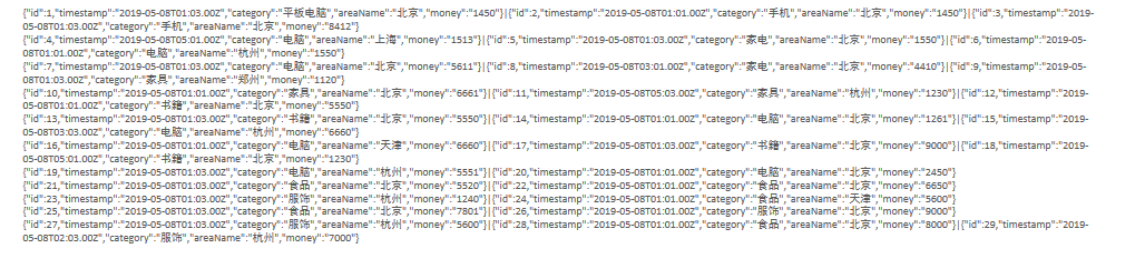
- 需求
- 各个城市销售额排名,从大到小
- 全部城市,有哪些商品类别在售卖
- 北京市有哪些商品类别在售卖
from pyspark import SparkConf,SparkContext
import os
import json
os.environ["PYSPARK_PYTHON"] = "E:\Python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("testSpark")
sc = SparkContext(conf=conf)
rdd = sc.textFile("./orders.txt")
# 将文件数据过滤为字典数据形式
# 数据中每一行的数据有些是两段有些是三段,所以使用flatMap进行解除嵌套
strJsonData = rdd.flatMap(lambda data:data.split("|"))
dictData = strJsonData.map(lambda data:json.loads(data))
# 城市销售额排名
saleData = dictData.map(lambda data:(data["areaName"],int(data["money"])))
saleNum = saleData.reduceByKey(lambda x, y:x+y)
salSort = saleNum.sortBy(lambda data:data[1], ascending=False, numPartitions=1)
print(salSort.collect())
# 全称是有那些商品类别在售卖
commodity = dictData.map(lambda data:data["category"])
print(commodity.distinct().collect())
# 北京市有那些商品类别在售卖
bjData = dictData.filter(lambda data:data["areaName"] == "北京")
bjCommodity = bjData.map(lambda data:data["category"])
print(bjCommodity.distinct().collect())
5.数据输出
5.1、输出为Python对象
collect算子【上述一直使用到的】
- 将RDD各个分区的数据,统一手机到Driver中,形成一个list对象
- rdd.collect()
from pyspark import SparkConf,SparkContext import os os.environ["PYSPARK_PYTHON"] = "E:\Python3.10.4\python.exe" conf = SparkConf().setMaster("local[*]").setAppName("testSpark") sc = SparkContext(conf=conf) rdd = sc.parallelize([1,2,3,4,5]) # collect算子,输出RDD为list对象 rdd_list: list = rdd.collect() print(rdd_list)reduce算子
- 对RDD数据集按照你传入的逻辑进行聚合
- 返回值同等与计算函数的返回值
sum = rdd.reduce(lambda a, b:a + b) print(sum)take算子
- 取RDD的前N个元素,组合成list返回
take_list = rdd.take(3)count算子
- 计算RDD有多少调数据,返回值为int
# count,统计RDD内有多少调数据,返回值为int print(rdd.count())
5.2、输出到文件中
saveAsTextFile算子
- 将RDD的数据写入文本文件中
from pyspark import SparkConf,SparkContext import os os.environ["PYSPARK_PYTHON"] = "E:\Python3.10.4\python.exe" os.environ["HADOOP_HOME"] = "E:\hadoop-3.0.0" conf = SparkConf().setMaster("local[*]").setAppName("testSpark") sc = SparkContext(conf=conf) # 数据1 修改RDD分区为1个 单个rdd rdd1 = sc.parallelize([1, 2, 3, 4, 5]) # 数据2 rdd2 = sc.parallelize([("Hello", 3), ("Spark", 5), ("Hi", 7)]) # 数据3 rdd3 = sc.parallelize([[1, 3, 5], [6, 7, 9], [11, 13, 11]]) # 输出到文件中 rdd1.saveAsTextFile("E:/TestPhoto/testOutputData/output01") rdd2.saveAsTextFile("E:/TestPhoto/testOutputData/output02") rdd3.saveAsTextFile("E:/TestPhoto/testOutputData/output03")注意事项
调用保存文件的算子,需要配置Hadoop依赖
下载Hadoop安装包
解压电脑任意位置
在Python代码中使用os模块,配置
import os os.environ["HADOOP_HOME"] = "HADOOP解压文件夹路径"下载winutils.exe,并放入Hadoop解压文件文件夹的bin目录内
下载hadoop.dll,并放入:C:/Windows/System32文件夹内
修改rdd分区为1个
- 方式1,SparkConf对象设置属性全局并行度为1
conf = SparkConf().setMaster("local[*]").setAppName("testSpark") # 修改RDD分区为1个 全局 conf.set("spark.default.parallelism","1")- 方式2,创建RDD的适合设置(parallelize方法传入numSlices参数为1)
# 数据2 rdd2 = sc.parallelize([("Hello", 3), ("Spark", 5), ("Hi", 7)], 1) # 数据3 rdd3 = sc.parallelize([[1, 3, 5], [6, 7, 9], [11, 13, 11]], 1)
6.综合案例
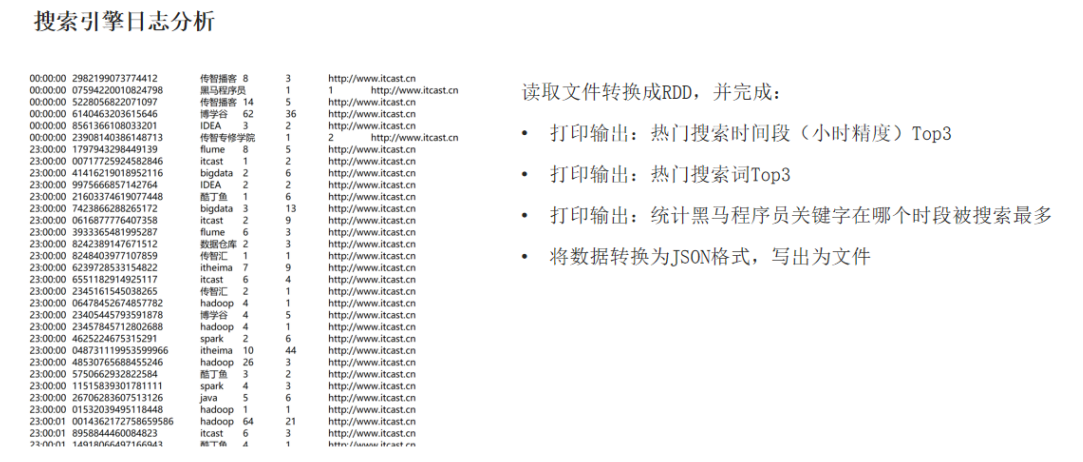
from pyspark import SparkConf,SparkContext
import json
import os
os.environ["PYSPARK_PYTHON"] = "E:\Python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("testSpark")
conf.set("spark.default.parallelism","1")
sc = SparkContext(conf=conf)
fileData = sc.textFile("./search_log.txt")
splitData = fileData.map(lambda data:data.split("\t"))
# 热门搜索时间段(小时精度)Top3
timeData = splitData.map(lambda data:(data[0].split(":")[0], 1)).\
reduceByKey(lambda a, b:a+b).\
sortBy(lambda data:data[1], ascending=False, numPartitions=1).\
take(3)
print(f"热门搜索时间段:{timeData}")
# 热门搜索词Top3
wordData = splitData.map(lambda data:(data[2], 1)).\
reduceByKey(lambda a, b:a+b).\
sortBy(lambda data:data[1], ascending=False, numPartitions=1).\
take(3)
print(f"热门搜索词Top3:{wordData}")
# 黑马程序员关键字哪个时段被搜搜的最多
wordTimeData = splitData.filter(lambda data: data[2] == "黑马程序员").\
map(lambda data: (data[0].split(":")[0],1)).\
reduceByKey(lambda a, b:a+b).\
sortBy(lambda data:data[1], ascending=False, numPartitions=1).\
take(1)
print(f"黑马程序员关键字在:{wordTimeData}被搜索的最多")
# 将数据转换为JSON格式,写出为文件
os.environ["HADOOP_HOME"] = "E:\hadoop-3.0.0"
jsonData = splitData.map(lambda data: json.dumps({"time":data[0],"user_id":data[1], "key_word":data[2], "rank1":data[3], "rank2":data[4], "url":data[5]}))
jsonData.saveAsTextFile("E:/TestPhoto/testOutputData/综合案例")