1.xpath
安装步骤
- 打开浏览器 -> 点击右上角小圆点 -> 更多工具 -> 扩展程序 -> 拖拽xpath插件到扩展程序中 -> 如果crx文件失效,修改插件后缀为zip -> 再次拖拽 -> 关闭浏览器冲i性能打开 -> ctrl+shift+x打开 -> 出现小黑框
安装lxml库
pip install lxml -i https://pypi.douban.com/simplexpath基本适用
- html代码
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"/> <title>Title</title> </head> <body> <ul> <li id="lilili">北京</li> <li>上海</li> <li>深圳</li> <li>武汉</li> </ul> <ul> <li id="l1" class="c1">大连</li> <li id="l2">锦州</li> <li id="c3">沈阳</li> <li id="c4">河南</li> </ul> </body> </html>解析本地文件
from lxml import etree tree = etree.parse("./data/01locationData.html") print(tree) # <lxml.etree._ElementTree object at 0x0000015C675FD180>解析服务器响应文件
tree = etree.HTML(url)
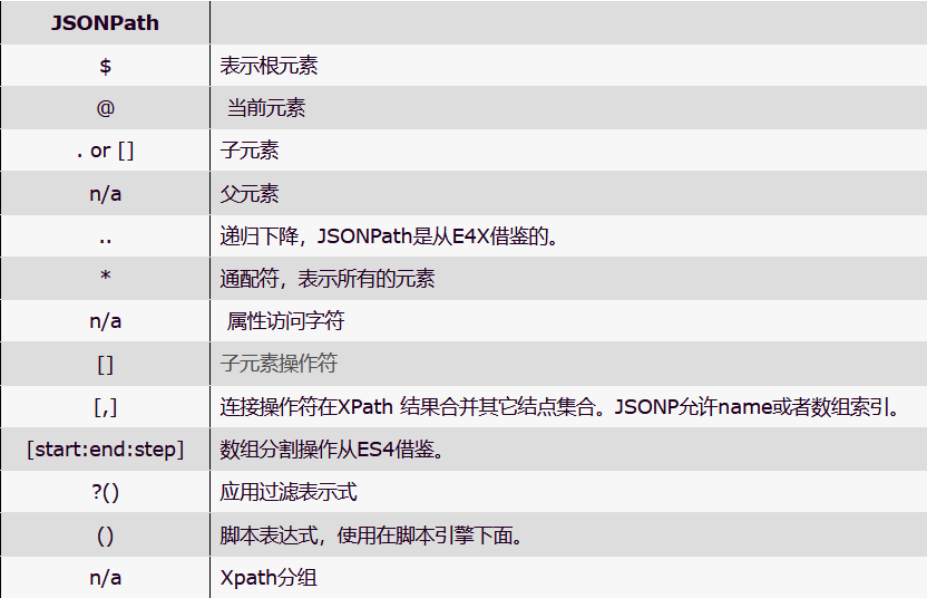
xpath基本语法
路径查询
- //:查询所有子孙节点,不考虑层级关系
- /:找直接子节点
tree = etree.parse("./data/01locationData.html") # 获取到指定标签——tree.xpath(xpath路径) # 查找ul下面的li liList = tree.xpath("//body/ul/li") print(len(liList))谓词查询 and 内容查询(text())
# 查找ul下面带有id属性的li:text()获取标签内容 liList = tree.xpath("//body/ul/li[@id]/text()") print(liList) # 找到id为l1的li标签 liList = tree.xpath("//body/ul/li[@id='l1']/text()") print(liList)属性查询
# 找到id=l1的li标签的class值 classValue = tree.xpath("//body/ul/li[@id='l1']/@class") print(classValue)模糊查询
# 查询id的值包含l的标签 liList = tree.xpath("//ul/li[contains(@id,'l')]/text()") print(liList) # 查询id的值以l开头的标签 liList = tree.xpath("//ul/li[starts-with(@id,'l')]/text()") print(liList)逻辑运算
# 查询id=l1 class=c1的标签 liList = tree.xpath("//ul/li[@id='l1' and @class='c1']/text()") print(liList) # | liList = tree.xpath("//ul/li[@id='l1']/text() | //ul/li[@id='l2']/text()") print(liList)
案例:站长素材图片抓取
# 下载前10页图片
# https://sc.chinaz.com/tupian/fengjing.html
# https://sc.chinaz.com/tupian/fengjing_2.html 2页
import urllib.request
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/112.0"
}
# 请求对象的定制
def createRequest(page):
url = None
if page == 1:
url = "https://sc.chinaz.com/tupian/fengjing.html"
else:
url = f"https://sc.chinaz.com/tupian/fengjing_{page}.html"
request = urllib.request.Request(url=url,headers=headers)
return request
# 发送请求获取HTML数据
def getContent(request):
response = urllib.request.urlopen(request)
return response.read().decode("UTF-8")
# 解析HTML数据并下载图片
def downLoad(content):
tree = etree.HTML(content)
imgs = tree.xpath("//img[@class='lazy']/@data-original")
print(imgs)
fileNames = tree.xpath("//img[@class='lazy']/@alt")
for i in range(0,len(imgs)):
urllib.request.urlretrieve(f"https:{imgs[i]}",f"./data/站长素材imgs/{fileNames[i]}.jpg")
if __name__ == '__main__':
startPage = int(input("请输入起始页数:"))
endPage = int(input("请输入结束页数:"))
for page in range(startPage,endPage+1):
# 请求对象的定制
request = createRequest(page)
content = getContent(request)
downLoad(content)
2.JsonPath
安装
pip install jsonpath使用
jsonData = json.load(open("json文件","r",encoding="UTF-8")) ret = jsonpath.jsonpath(jsonData,"jsonpath语法")API
案例
- json
{ "store": { "book": [ { "category": "修真", "author": "六道", "title": "坏蛋是怎样练成的", "price": 8.95 }, { "category": "修改", "author": "天蚕土豆", "title": "斗破苍穹", "price": 12.99 }, { "category": "修真", "author": "唐家三少", "title": "斗罗大陆", "isbn": "0-553-21311-3", "price": 8.99 }, { "category": "修真", "author": "南派三叔", "title": "星辰变", "isbn": "0-395-19395-8", "price": 22.99 } ], "bicycle": { "author": "老马", "color": "黑色", "price": 19.95 } } }- 练习
import json import jsonpath # 读取文件的json数据 data = json.load(open("./data/store.json","r",encoding="UTF-8")) # 书店所有书的作者 authors = jsonpath.jsonpath(data,"$.store.book[*].author") print(authors) # 所有的作者 authors = jsonpath.jsonpath(data,"$..author") # store下面的所有的元素 eles = jsonpath.jsonpath(data,"$.store.*") print(eles) # store下面所有的price prices = jsonpath.jsonpath(data,"$.store..price") print(prices) # 第三本书 book = jsonpath.jsonpath(data,"$..book[2]") print(book) # 最后一本书 lastBook = jsonpath.jsonpath(data,"$..book[(@.length-1)]") print(lastBook) # 前两本书 twoBook = jsonpath.jsonpath(data,"$..book[0,1]") print(twoBook) twoBook = jsonpath.jsonpath(data,"$..book[:2]") print(twoBook) # 过滤出所有包含isbn的书 isbnBook = jsonpath.jsonpath(data,"$..book[?(@.isbn)]") print(isbnBook) # 哪几本书超过了10块钱 price = jsonpath.jsonpath(data,"$..book[?(@.price>10)]") print(price)案例:淘票票
import urllib.request
url = "https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1683468179654_108&jsoncallback=jsonp109&action=cityAction&n_s=new&event_submit_doGetAllRegion=true"
headers = {
# ':authority': 'dianying.taobao.com',
# ':method': 'GET',
# ':path': '/cityAction.json?activityId&_ksTS=1683468179654_108&jsoncallback=jsonp109&action=cityAction&n_s=new&event_submit_doGetAllRegion=true',
# ':scheme': 'https',
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
#'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'bx-v': '2.2.3',
'cookie': '_m_h5_tk=2e52ae6f1f49a2acbc0a9902700ab55e_1683476720174; _m_h5_tk_enc=502c83b66d99824dbb01b11b0f40c853; cna=MJ3eHLP25HICAd2wjNZV9MbR; xlly_s=1; t=298f6d484f25e13c9fb30f39f847d5fb; cookie2=1370b1eaf675288cf32a03a7f87f9fbf; v=0; _tb_token_=e8533573fef57; tb_city=110100; tb_cityName="sbG+qQ=="; tfstk=cpPFBNOnK6CEeZ4RDfczbK_CSFMdZ3oocCuqKgC1xjyN7AHhiPx-ScCx748wqvf..; l=fBPYvXl4NheAYKkNBO5Cnurza77OoIOb4sPzaNbMiIEGa6sCtF9GPNC_EFHeSdtjgTCvSetrBZyM6dLHR3A0hc0c07kqm0SrFxvtaQtJe; isg=BMfHKcPPbwlKQ-uFJstGSu1mVnuRzJuukAonhZm149Z9COfKoZ3I_lLOqshW4HMm',
'referer': 'https://dianying.taobao.com/?spm=a1z21.3046609.city.1.32c0112acorA4f&city=110100',
'sec-ch-ua': '"Chromium";v="112", "Google Chrome";v="112", "Not:A-Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode("UTF-8")
# 修改json数据
content = content.split("(")[1].split(")")[0]
# 下载到本地——jsonpath只能解析本地json数据
with open("./data/taopiaopiao.json","w",encoding="UTF-8") as f:
f.write(content)
# jsonpath解析数据,得到北京市全部的城市
import jsonpath
import json
data = json.load(open("./data/taopiaopiao.json","r",encoding="UTF-8"))
cities = jsonpath.jsonpath(data,"$..regionName")
print(cities)
3.BeautifulSoup
概述
- 简称bs4,和lxml一样,是一个html解析器,主要功能也是解析和提取数据
- 优点:接口设计人性化,使用方便
- 缺点:效率没有lxml效率高
安装
pip install bs4创建对象
- 解析服务器响应的文件
from bs4 import BeautifulSoup soup = BeautifulSoup(response.read().decode("UTF-8"),"lxml")- 解析本地文件
soup = BeautifulSoup(open("文件.html"),"lxml")
【html演示代码】
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
<ul>
<li id="l1">张三</li>
<li id="l2">李四</li>
<li>王五</li>
<a href="" class="a1">马浩楠</a>
<span>哈哈哈哈</span>
</ul>
</div>
<a href="" title="a2">百度</a>
<div id="d1">
<span>哈哈</span>
</div>
<p id="p1" class="p1">嘿嘿嘿嘿</p>
</body>
</html>
节点定位
- 根据标签名查找节点
from bs4 import BeautifulSoup # 解析本地文件 # open()默认打开的文件编码格式是gbk,所以打开文件的时候需要指定编码 soup = BeautifulSoup(open("./data/bs4基本使用.html",encoding="UTF-8"),"lxml") # 根据标签名查找节点 # 找到第一个符合条件的数据 print(soup.a) # <a class="a1" href="">马浩楠</a> # 获取标签的属性和属性值 # {'href': '', 'class': ['a1']} print(soup.a.attrs)函数
- .find(返回一个对象)
# 1.1 返回第一个符合条件的数据——soup.find print(soup.find("a")) # 1.2 根据title的值来找到对应的标签对象 print(soup.find("a",title="a2")) # 1.3 根据class的值来找到对应的标签队形【注意:class需要添加下划线 class_】 print(soup.find("a",class_="a1"))- .find_all(返回一个列表)
print(soup.find_all("a")) # 如果想获取的是多个标签的数据,那么find_all的参数为列表形式传递即可 print(soup.find_all(["a","span"])) # limit:查找前几个数据 print(soup.find_all("li",limit=2))- .select(根据选择器得到节点对象)【推荐】
# 3.select(推荐用法):返回的是列表,且是多个数据 # 获取所有a标签 print(soup.select("a")) # 通过class=a1 获取标签 print(soup.select(".a1")) # 通过id=l1 获取标签 print(soup.select("#l1")) # 属性选择器:查找到li标签中有id属性的标签 print(soup.select("li[id]")) # 查找到li标签中,id=l2的标签 print(soup.select("li[id='l2']")) # 层级选择器 # 1.后代选择器:找到div下面的li print(soup.select("div li")) # 2.子代选择器(某标签的第一级子标签):找到div下的ul下的li 【注意:很多计算机语言中,如果不加空格不会输出内容,但在bs4中不会报错也会显示内容】 print(soup.select("div > ul > li")) # 3.组合选择器:找到a标签和li标签的所有对象 print(soup.select("a,li"))节点信息
- 获取节点内容
# 获取节点内容 obj = soup.select("#d1")[0] # 如果标签对象中只有内容,那么obj.string和obj.get_text()都可以适用 # 如果标签对象中除了内容还有标签,那么string就获取不到数据,get_text()【推荐】可以获取到 print(obj.string) print(obj.get_text())- 获取节点的属性名字
obj = soup.select("#p1")[0] print(obj.name) # name是标签的名字 print(obj.attrs) # .attrs是将该标签的所有属性作为字典返回- 获取节点的属性值
print(obj.attrs.get("class")) # 【推荐方式】 print(obj.get("class")) print(obj['class'])案例:爬取星巴克数据
import urllib.request
url = "https://www.starbucks.com.cn/menu/"
response = urllib.request.urlopen(url=url)
content = response.read().decode("UTF-8")
# xpath://ul[@class='grid padded-3 product']//strong/text()
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,"lxml")
# 获取产品的名称
nameList = soup.select("ul[class='grid padded-3 product'] strong")
names = []
for i in nameList:
names.append(i.get_text())
4.Selenium
概述
- Selenium是一个用于Web应用程序测试的工具
- Selenium测试直接运行在浏览器中,像真正的用户在操作一样
- 也支持无界面浏览器操作
使用原由
- 模拟浏览器功能,自动执行网页中的js代码,实现动态加载
安装
- 谷歌浏览器驱动下载
- 映射表
- pip install selenium
基本使用
# 1.导入selenium from selenium import webdriver # 2.创建浏览器操作对象 path = "./chromedriver.exe" browser = webdriver.Chrome(path) # 3.访问网站 browser.get("https://www.baidu.com/") browser.get("https://www.jd.com/") # page_source获取网页源码 content = browser.page_source print(content)元素定位:自动化要做的就是模拟鼠标和键盘来操作这些元素
from selenium import webdriver from selenium.webdriver.common.by import By # 创建浏览器操作对象 path = "./chromedriver.exe" browser = webdriver.Chrome(path) browser.get("https://www.baidu.com") # 元素定位 # 1.根据元素id查找对象 botton = browser.find_element("id","su") print(botton) # 2.根据元素标签属性值来获取对象 print(browser.find_element("name","wd")) # 3.通过xpath来定位元素 print(browser.find_element("xpath","//input[@id='su']")) # 4.根据标签的名字来获取对象 print(browser.find_elements("tag name","input")) # 5.通过bs4语法来定位元素 print(browser.find_element("css selector","#su")) # 6.获取当前页面所有的链接标签,根据链接标签的内容来定位某一个 print(browser.find_element(By.LINK_TEXT,"新闻"))访问元素信息
from selenium import webdriver path = "./chromedriver.exe" browser = webdriver.Chrome(path) browser.get("https://www.baidu.com") # 查找到id为su的class属性值 botton = browser.find_element("id","su") print(botton.get_attribute("class")) # 获取标签名 print(botton.tag_name) # 获取标签内容 a = browser.find_element("link text","新闻") print(a.text)交互
点击:click()
输入:send_keys()
后退操作:browser.back()
前进操作:browser.forword()
模拟JS滚动
js = "document.doucmentElement.scrollTop=100000" browser.execute_script(js)获取网页代码:page_source
退出:browser.quit()
from selenium import webdriver # 创建浏览器对象 path = "./chromedriver.exe" browser = webdriver.Chrome(path) url = "https://www.baidu.com" browser.get(url) import time time.sleep(3) # 获取文本框对象 input = browser.find_element("id","kw") # 在文本框中输入 周杰伦 input.send_keys("周杰伦") time.sleep(2) # 获取百度一下按钮 button = browser.find_element("id","su") # 点击按钮 button.click() time.sleep(2) # 滑动到底部 js_bottom = "document.documentElement.scrollTop=100000" browser.execute_script(js_bottom) time.sleep(2) # 点击下一页 a = browser.find_element("xpath","//a[@class='n']") a.click() time.sleep(2) # 回到上一页 browser.back() time.sleep(2) # 回去 browser.forward() time.sleep(10) # 退出 browser.quit()Chrome handless
- 配置
from selenium import webdriver from selenium.webdriver.chrome.options import Options chrome_options = Options() chrome_options.add_argument('--headless') chrome_options.add_argument('--disable‐gpu') path = r'C:\Users\12744\AppData\Local\Google\Chrome\Application/chrome.exe' chrome_options.binary_location = path browser = webdriver.Chrome(chrome_options=chrome_options)- 封装
# 封装的handless def shareBrowser(): chrome_options = Options() chrome_options.add_argument('‐‐headless') chrome_options.add_argument('‐‐disable‐gpu') path = r'C:\Users\12744\AppData\Local\Google\Chrome\Application/chrome.exe' chrome_options.binary_location = path browser = webdriver.Chrome(chrome_options=chrome_options) return browser browser = shareBrowser() url = "https://www.baidu.com" browser.get(url) # 拍照截图效果 browser.save_screenshot("./baidu.png")
5.requests
文档
安装
- pip install requests
基本使用
import requests url = "http://www.baidu.com" response = requests.get(url=url) # 一个类型六个属性 # Response类型 print(type(response)) # 设置响应编码格式 response.encoding = "UTF-8" # 以字符串的形式返回网页的源码 print(response.text) # 返回url地址 print(response.url) # 返回二进制数据 print(response.content) # 返回状态码 print(response.status_code) # 返回响应头 print(response.headers)get请求
import requests url = "http://www.baidu.com/s" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/112.0", } data = { "wd":"北京" } # url:请求资源路径,params:参数,kwargs 字典 response = requests.get(url=url, params=data, headers=headers) response.encoding = "UTF-8" content = response.text print(content)- 定制参数
- 参数使用params传递
- 参数不需要urlencode传递
- 不需要请求对象的定制
- 请求路径中的?【可加可不加】
- 定制参数
post请求
import requests url = "https://fanyi.baidu.com/sug" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/112.0", } data = { "kw":"love" } # url:请求地址 data:请求参数 kwargs:字典 response = requests.post(url=url, data=data, headers=headers) content = response.text import json result = json.loads(content) print(result)- get/post区别
- get请求的参数名字是params,post请求的参数名字是data
- 请求资源后面可以不加?
- 不需要手动编解码
- 不需要做请求对象的定制
- get/post区别
代理
- 在请求中设置proxies参数(字典类型)
import requests url = "http://www.baidu.com/s" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/112.0", } data = { "wd":"ip" } proxy = { "http":"183.236.232.160:8080" } response = requests.get(url=url, params=data, headers=headers, proxies=proxy) with open("./daili.html","w",encoding="UTF-8") as f: f.write(response.text)cookie定制
```
识别验证码
进入主页面,绕过验证码
登录时,需要的参数有很多
__VIEWSTATE: nK3MzlPEMF5PrWU6t0vQz34+572tw1zBOr6VBYWwHviJFJK+ExmSjai9Tdetxn3jPGxQetiK0ZoIn/WezUUtOrnPbAq1Sv24I0P7cXEgZDVYLlzqQ2FTzOz9VXQes2V0aLowq+eVeorUFN0H9tdDb4l1eoo=
__VIEWSTATEGENERATOR: C93BE1AE
from: http://so.gushiwen.cn/user/collect.aspx
email: 15836559567
pwd: mhn0102222
code: 6xbb
denglu: 登录
观察到 VIEWSTATE VIEWSTATEGENERATOR code 是一个可以变化的量
难点:VIEWSTATE VIEWSTATEGENERATOR 一般情况下看不到数据,都是在页面源码当中(隐藏input)
获取页面源码,拿到这两个隐藏input的值并解析
难点2:验证码
import requests url = "https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx"
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/112.0", } response = requests.get(url=url, headers=headers)
获取到源码,定位两个隐藏input框并拿到值——bs4
from bs4 import BeautifulSoup soup = BeautifulSoup(response.text,"lxml")
viewState = soup.select("#VIEWSTATE")[0].attrs.get("value") viewStateGenerator = soup.select("#VIEWSTATEGENERATOR")[0].attrs.get("value")
获取code值
codeImg = soup.select("#imgCode")[0].attrs.get("src") codeUrl = "https://so.gushiwen.cn"+codeImg
使用urlretrieve下载,存在坑:因为当进入这个页面的时候就已经是一次请求了,再次发送的请求和要进入登录的时候请求补一个
requests中有一个方法 session(),通过session获取到请求对象,就可以使得两次请求为一次请求
""" import urllib.request urllib.request.urlretrieve(codeUrl,"./code.jpg") """ session = requests.session()
验证码url内容
responseCode = session.get(codeUrl)
此时使用.content二进制返回,因为是图片需要下载
wb模式就是将二进制数据写入到文件
with open("./code.jpg","wb") as f: f.write(responseCode.content)
通过输入来获取到code值(在图片中查看)
code = input("请输入验证码值:")
通过超级鹰来识别验证码
from requests.chaojiying import Chaojiying_Client chaojiying = Chaojiying_Client('15836559567', 'mhn010220', '948151') im = open('./code.jpg', 'rb').read() print(chaojiying.PostPic(im, 1004).get("pic_str")) code = chaojiying.PostPic(im, 1004).get("pic_str")
三个值都有了 发送请求进入到登录页面并返回到网页源码
data = { "VIEWSTATE": viewState, "VIEWSTATEGENERATOR": viewStateGenerator, "from": "http://so.gushiwen.cn/user/collect.aspx", "email": "15836559567", "pwd": "mhn010220", "code": code, "denglu": "登录" } response = session.post(url=url,data=data,headers=headers) with open("./古诗文网.html","w",encoding="UTF-8") as f: f.write(response.text)
- 使用超级鹰第三方平台来解析验证码步骤
- 官网:https://www.chaojiying.com/
- 开发文档

- Python语言Demo下载
- 解压后,将两个文件放入当前项目中(a.jpg)(chaojiying.py)
```python
#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def PostPic_base64(self, base64_str, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
'file_base64':base64_str
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
chaojiying = Chaojiying_Client('15836559567', 'mhn010220', '948151') #用户中心>>软件ID 生成一个替换 96001
im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print(chaojiying.PostPic(im, 1004).get("pic_str")) #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
#print chaojiying.PostPic(base64_str, 1902) #此处为传入 base64代码